Attention Mechanism
Neural Turing Machines
Instead of specifying a single location, the RNN gives “attention distribution” which describe how we spread out the amount we care about different memory positions. As such, the result of the read operation is a weighted sum.
Attentional Interfaces
We’d like attention to be differentiable, so that we can learn where to focus. To do this, we use the same trick Neural Turing Machines use: we focus everywhere, just to different extents.
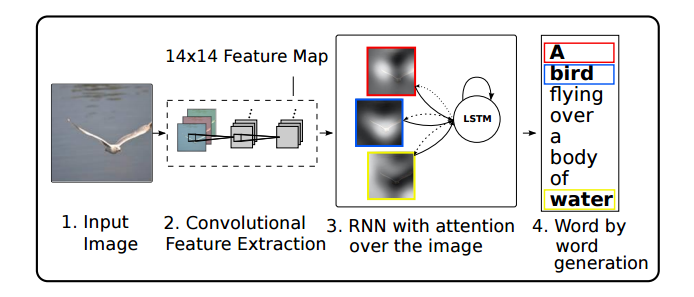
Attention can also be used on the interface between a convolutional neural network and an RNN. This allows the RNN to look at different position of an image every step. One popular use of this kind of attention is for image captioning. First, a conv net processes the image, extracting high-level features. Then an RNN runs, generating a description of the image. As it generates each word in the description, the RNN focuses on the conv nets interpretation of the relevant parts of the image. We can explicitly visualize this:

注意机制是由人类视觉注意所启发的,是一种关注图像中特定部分的能力。注意机制可被整合到语言处理和图像识别的架构中以帮助网络学习在做出预测时应该「关注」什么。
技术博客:深度学习和自然语言处理中的注意和记忆链接
Attention是选择显著区域的人眼视觉过程,这方面的算法模型注重给出fixation-prediction,典型的有Itti和Koch 1998年给出的视觉注意机制模型,attention主要是从人眼产生注意的过程和视觉系统的特征研究算法模型。
应用
1. Machine Translation
最早将Attention-based model引入NLP的就是2015年ICLR,Bahdanau的[《Neural machine translation by jointly learning to align and translate》][2]。
The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixedlength vector.
Motivation
传统翻译模型将整句的信息压缩至定长向量,使得长句上的翻译效果差。
soft-align:在进行翻译时,虽然语序会变,但大体的语义部分是有对应关系的,如果能找到这个关系,就不用整句整句encode。
Approach
新模型RNNsearch:
对每一个target word ,都计算一个context vector ——用softmax刻画“expected annotation”。究竟对应哪一个annotation,可以看成一种分布(多分类),这样就可以用一个权重/概率的期望来刻画。
- 对齐(Align)与翻译同时进行。
2. Image Caption
《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention* 》
主要思想还是和上次讲的机器翻译类似:
看成是multinoulli分布
而这里的context vector计算为:
Attention can also be used on the interface between a convolutional neural network and an RNN. This allows the RNN to look at different position of an image every step. One popular use of this kind of attention is for image captioning. First, a conv net processes the image, extracting high-level features. Then an RNN runs, generating a description of the image. As it generates each word in the description, the RNN focuses on the conv nets interpretation of the relevant parts of the image. We can explicitly visualize this:
现在的问题:
- attention主要应用在sequence to sequence中。而这里还是解决分类问题,输出不是sequence而是vector
Encoder : Bidirectional RNN (BiRNN) for Annotation
相当于做两次BiRNN:横向和纵向,再concate
{% math %}
a\_i=
\left(
\begin{array}{c}
\overrightarrow{h}\\
\overleftarrow{h} \\
\overrightarrow{h}'\\
\overleftarrow{h}'
\end{array}
\right)
{% endmath %}
concate: forward+backward :
- 输出:`[time][batch][cell_fw.output_size + cell_bw.output_size]`
# Forward direction cell
lstm_fw\_cell = tf.nn.rnn_cell.BasicLSTMCell(num_hidden, forget_bias=0.0)
# Backward direction cell
lstm_bw\_cell = tf.nn.rnn\_cell.BasicLSTMCell\(num\_hidden, forget\_bias=0.0\)
pre_encoder\_inputs, output\_state\_fw, output\_state\_bw = tf.nn.bidirectional\_rnn\(lstm\_fw\_cell, lstm\_bw\_cell, lstm_inputs, initial_state_fw=None, initial_state\_bw=None,dtype=tf.float32, sequence\_length=None, scope=None\)
encoder\_inputs = \[e\*f for e, f in zip\(pre\_encoder\_inputs, encoder\_masks\[:seq\_length\]\)\]
- initial_states : 2D batch_size X cell.state_size
initial\_state = concate\(output\_state\_fw, output\_state\_bw\)
\#-> 2 x num\_hidden
Decoder :
初始化:
- memory state
- hidden state
在每一个时刻,根据三者:
:前一时刻隐藏层状态
隐藏层像是一个混沌,记忆、遗忘皆源于此,几乎时刻变化着。
这里时间$t$的概念也是伴随着一个个小方格源源不断地输入。
之前输出的结果们
: 当前输入的context vector
- 这里应该对应于当前(时刻)输入的方格相关(relevant)的方格状况。
计算当前输出结果。
重头戏:设计一套机制,从计算 ,重复一遍,这里的是对应个方格的annotation vector,亦可理解为feature vector。而对每一个方格,使用$\phi$计算一个正权重
可理解为折衷考虑时,方格的重要程度。就好像一伙人投票决定其中一个人是好是坏,里面总有几个和这个当事人关系密切的人,那么,在最终判断时这些人的意见就应该发挥更大的作用。这里的判断好坏也是对应有无裂缝这种二项问题来说的,真实世界哪有这么黑白分明,大多数问题的搜索空间都是很庞大的,比如Image Caption对应的是词典空间,进行投票的则是image各处的“像素兵团”。
作为引子,这时我们提出一个attention model :
代表某个小方格的+上一刻的混沌=?
经过这里的softmax,摇身成为,这样又可理解为“重要性归一化”后的概率,成为bounded的了。
我们注意到,这里有两个下标,继续上面的例子,大概是贼窝子里自个儿人相互表决了,现在倒霉的是小,而上面的计算得出了所有人(包括小自己)意见被考虑的概率。最后是不是很像计算期望?这样我们几乎完成了一个人的名誉(reputation)计算方法!
这一步意图已经很明显了。。。每个人的名誉+意见被考虑的概率 = “倒霉蛋”小处于“水深火热”之中。
试想一下,某个名誉很好的小“nice”对小评价概率大,就会在小$t$的名誉话语权里占很大一席了,小的context也就相对nice。另外,这里举的例子是二维空间,人有千面,更高维的牵扯就剪不断理还乱了。
现在混沌外的事理清了,来看看混沌里头:
盘古初开天地需要两个种子:
: memory state
: hidden state
最后怎么知道呢?当然还是概率呀~
按道理来说。这里不应该是,如果是从左到右逐行扫描小方格作为输入,很显然在换行的时候前后两个方格没什么逻辑联系,反而还是上下左右4个或8个的输出结果更值得参考。相当于{周围格}负责本地特征,负责全局特征投票,的考验则在于及时更新状态,选择遗忘/记忆。
seq2seq
这里用的是Tensorflow自产的`Seq2seq_model`,本来应该是用于机器翻译这种序列到序列的编解码模型,输出实际上是`target_vocab_size`相关的。这里做些改动用到我们的二分类模型上。
首先构造内部的多层RNN网络:
attn_numattn_layer
single\_cell = tf.nn.rnn\_cell.BasicLSTMCell\(attn\_num\_hidden, forget\_bias=0.0\)
cell = tf.nn.rnn\_cell.MultiRNNCell\(\[single\_cell\] \* attn\_num\_layers\)
num\_hidden = attn\_num\_layers \* attn\_num\_hidden
默认是LSTM,可以选择GRU(use_gru)
- `forward_only` 训练时还要backward,测试时则不用
In this context "attention" means that, during decoding, the RNN can look up
information in the additional tensor attention_states, and it does this by
focusing on a few entries from the tensor. This model has proven to yield
especially good results in a number of sequence-to-sequence tasks. This
implementation is based on http://arxiv.org/abs/1412.7449 (see below for
details). It is recommended for complex sequence-to-sequence tasks.
Adaptive Computation Time
Neural Programmer
Reference
[2]: http://www.cl.uni-heidelberg.de/courses/ws14/deepl/BahdanauETAL14.pdf