背景介绍
在许多实际应用中,我们需要解决的关键问题是如何对多个彼此关联的变量进行预测。譬如自然语言处理中的词性标注问题,或者机器视觉里的图像标注任务,抑或是对DNA链上基因的分割。1 在这些应用中,我们希望通过观测到的特征向量 $\mathbf x$ 来预测由随机变量组成的输出向量$\mathbf y=(y_0,y_1,\ldots,y_T)$。图模型很自然地建立了实体之间的结构化关系,因而被用于表示联合概率分布$p(\mathbf y,\mathbf x)$。
本文的研究背景是像素级的图像标注任务,这里表示一张大小为$\sqrt T \times \sqrt T$的图片,每个$x _i$都代表一个像素。为使问题简化,这里考虑黑白图片,则$x _i$为取值范围0~255的实数。每个$y _i$就代表该像素的标签(label),比如我正在做的路面裂缝识别任务中,标签就只有两种:$+1$代表裂缝,$0$代表正常路面。
假设图$G=(V,E)$,其中$V={X_1,X_2,\ldots,X_N}$,全局观测为$I$。使用Gibbs分布,$(I,X)$可被建模为CRF
$\varphi_p(x_i.x_j)$是对 $i$、$j$ 同时分类成$x_i$、$x_j$的能量。

接下来的内容安排为:第二章首先引入条件随机场的概念,之后举例说明其与其他模型的区别,最后从原理上介绍它在图像标注中的应用;第三章则是近年来相关工作的简要阐述。
二、条件随机场
2.1 概念引入
- $Y$:一系列随机变量的集合;
- 概率图模型:无向图$G=(V,E)$表示概率分布$P(Y)$,节点$v\in V$表示一个随机变量$Y_s$,$s\in1,2,\ldots|Y|$ ;边$e\in E$表示随机变量之间的概率依存关系;
- 概率无向图模型:如果联合概率满足成对、局部或者全局马尔科夫性,就称该联合概率分布为无向图模型,或者马尔科夫随机场。最大特点:易于因子分解。这里的随机场指的就是由无向图定义的特定分布。
indicator function:
条件随机场(conditional random field,以下简称CRF):假定我们关心的概率分布$p$可以通过$A$个形如$\Psi_a(\mathbf y_a)$的因子(factor)的乘积来表示。
其中为规一化因子,使得在0~1。
这些factor也称做local function或compatibility function。而在图中,与因子节点(factor node)$\Psi_a$相连的所有变量节点(variable node)都是$\Psi_a$的参数之一。所以factor graph描述的是分布$p$分解为一系列local function的方式。
2.2 判别式模型和产生式模型
通常看到一个新的模型,我们总习惯和已知的进行比较。朴素贝叶斯和逻辑回归模型之间的一个重要区别是,朴素贝叶斯是产生式模型(generative model),它基于联合分布$p(\mathbf x,\mathbf y)$建模,而逻辑回归是判别式模型(discriminative model),它直接对条件分布建模。
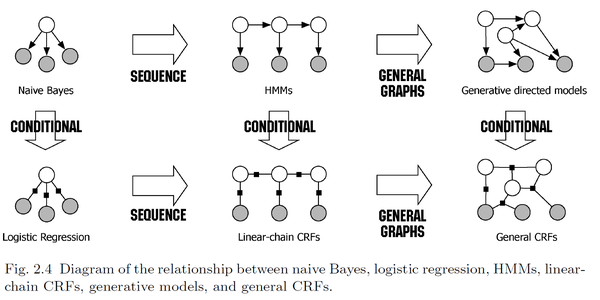
对条件分布$p(\mathbf y|\mathbf x)$建模,不包括对$p(\mathbf x)$ 建模($p(\mathbf x)$对分类来说无关紧要)。对$p(\mathbf x)$建模非常困难,因为$p(\mathbf x)$包含很多相互依赖的特征。比如在命名实体识别(Named- Entity Recognition,NER)应用中,HMM只依赖一个特征,即这个词本身,但是很多词,特别是一些特定的名字可能没有出现在训练集合中,因此词本身这个特征是未知的,为了标注未登陆词,我们需要利用词的其他的特征,如词性、相邻词、前缀和后缀等。
这里以HMM和Linear-chain CRF为例说明这两种模型的区别。
除了上面说的NER,在做词性标注任务(Part-of-Speech tagging, POS)的时候我们也常使用HMM模型,$\mathbf y$就是 word对应的词性(label),的是它的观测(word)。
- transition probability :$p(yt|y{t-1})$ 不同状态(label)之间的转移概率
- emission probability:$p(x_t|y_t)$ 由状态到观测(word)的发射概率
首先,我们可以将HMM重写为更一般化的形式:
其中$\theta={\theta{ij},\mu{oi}}$是分布的实值参数。只需要设定:
则与上述HMM等价。通过引入特征函数的概念:
- 对每一个转移$(i,j)$有$f{ij}(y,y',x)=\mathbf 1{{y=i}} \mathbf 1_{{y'=j}}$;
- 对每一个发射$(i,o)$有$f{io}(y,y',x)=\mathbf 1{{y=i}} \mathbf 1_{{x=o}}$;
- 特征函数$fk$遍历所有$f{ij}$和$f_{io}$。
这就得到了满足因子分解形式的Linear-chain CRF:
我们已经看到当联合分布为HMM的形式时,相应的条件概率分布为线性链式的CRF,在HMM中状态$i$到状态$j$的转移概率总是相同的,和当前的输入无关,但是在CRF中,我们可以通过加入特征:
来使得状态$i$到状态$j$的转移概率和当前输入有关。实际上,这也是CRF应用于图像标注的优势所在。
2.2 在图像标注中的应用
图像的一个重要特性是:相邻像素的标注趋向于一致。因此,我们可以通过设置一个的先验(prior)分布来融入该特性,使得预测趋向于“平滑”。目前最常用的prior是马尔可夫随机场(Markov random field,以下简称MRF),它是一个无向图,且有两种因子(factor):
- 关联标签$y_i$和对应的像素$x_i$ :
- 鼓励相邻标签$y_i$和$y_j$保持一致
这里用$\mathscr N$表示像素的相邻关系,则$(i,j)\in \mathscr N$意味着$x_i$ $x_j$相邻。通常$\mathscr N$是一个$\sqrt T \times \sqrt T$的网格。
这里的$\Psi$是鼓励平滑性的因子,比较通用的设置是:
通常$\alpha<1$,可理解为对差异的惩罚。
MRF的一个不足之处在于难引入关系数据中的局部特征,因为这时$p(\mathbf x|\mathbf y)$结构会很复杂。 CRF和MRF很相似。假定$q(x_i)$表示基于$x_i$周围区域的特征向量,例如颜色直方图或图像梯度。此外,$\nu(x_i,x_j)$描述$x_i$与$x_j$之间的关系,从而考虑$x_i$与$x_j$的异同。 这里就可以定义$\nu(x_i,x_j)$为$q(x_i)$和$q(x_j)$中特征的叉积。
为了让问题更加清楚,考虑MRF中的$\Psi(y_i,y_j)$,尽管它鼓励一致性,但方式不灵活。如果$x_i$ $x_j$的 标签不同,我们会预期它们的灰度也不同,因为不同物体总是色调不同。所以相比于标签边界出现在灰度悬殊的像素之间,出现在灰度相似的像素之间更“不合常理”。然而,MRF中的$\Psi$对这两种情况的惩罚相同,使得能量计算和像素值无关。为了解决这个问题,人们提出了下面的特征选择方法:
把上述所有加起来,就得到了CRF模型:
这种简单的CRF模型可通过多种方式改进:
- 特征函数$q$和$\nu$可以设计得更加复杂,例如考虑图片的形状和纹理,或者依赖于图像的全局特征而不是局部区域;
- 可以使用标签之间更加复杂的图结构而不是网格(grid),譬如可以根据标签区域定义因子(factor)。
三、相关工作
近年来已有许多研究者将CRF 应用于 pixel-wise 的图像标记(其实就是图像分割),从而实现分割边界的平滑化,进而提升正确率。例如Koltun等人使用全连接CRF、高斯核线性组合来定义边界能量实现的像素级图片标注任务,实验结果大幅改进了图像分割和标注的正确率3。接着,S Zheng等人通过将CRF实现为RNN,在模型优化过程进行端到端训练进一步提高了标注效果。2他们主要是利用条件随机场构造图像分割能量函数:
这里的$E$可以理解为能量,也就是cost。其中$\varphi_u(x_i)$是将像素$i$标记为$x_i$的inverse likelihood,也就是2.3中的特征函数$f(y_i,x_i)$,$\varphi_p(x_i.x_j)$是将$i$、$j$同时标记为$x_i$、$x_j$的能量,即2.3中的特征函数$g(y_i.y_j,x_i,x_j)$。对于CRF在计算机视觉中的应用,相信未来还会有更多探索。
四、参考文献
1. Sutton, Charles, and Andrew McCallum. "An introduction to conditional random fields." arXiv preprint arXiv:1011.4088 (2010). ↩
2. Zheng, Shuai, et al. "Conditional random fields as recurrent neural networks." Proceedings of the IEEE International Conference on Computer Vision. 2015. ↩
3. Koltun, Vladlen. "Efficient inference in fully connected crfs with gaussian edge potentials." Adv. Neural Inf. Process. Syst (2011). ↩