应用场景
通话录音内容审核功能:关键词检索,实现内容审核。
- 首先要进行音频预处理,包括音频格式转码、语音降噪等,然后存储处理后的文件;
- 把结果反馈给业务网关,由音频比对对已知录音片段进行检测,如果有匹配这些录音片段就反馈结果——存在诈骗信息。
- 如果经过音频比对没有发现诈骗信息,就调用关键词检索服务。
研究背景
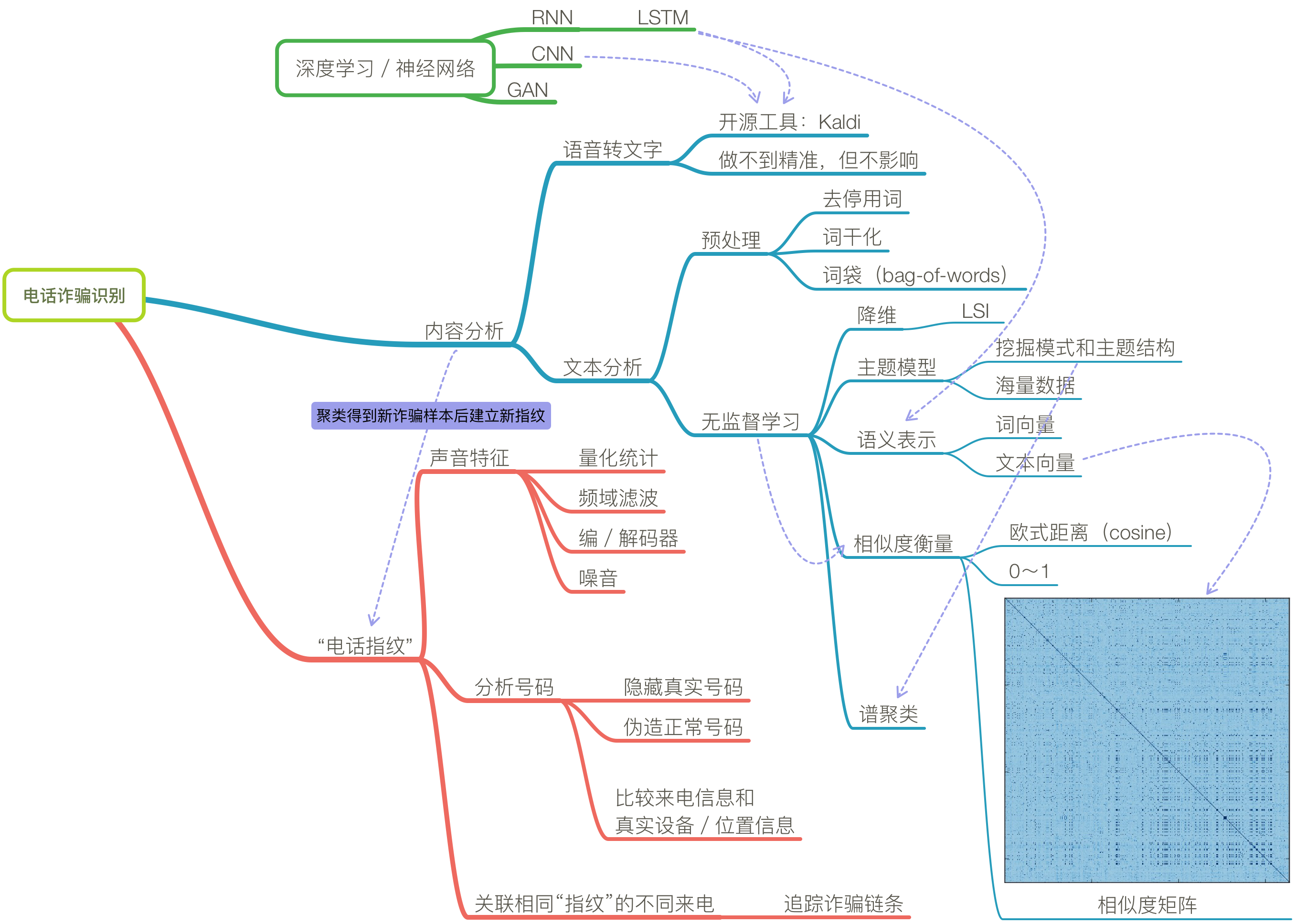
音频可分为有内容和无内容两种。针对不同的数据类型有不同的检测技术。针对说话内容有语音识别、关键词检索等;针对语种的判别有语种识别技术;针对说话人的识别有声纹识别技术;针对说话内容无关的通常采用音频对比的技术进行检测。
无内容:音频对比技术
音频对比主要是从音频信号中提取特征,通过特征进行比对来检索。参考案例dejavu。
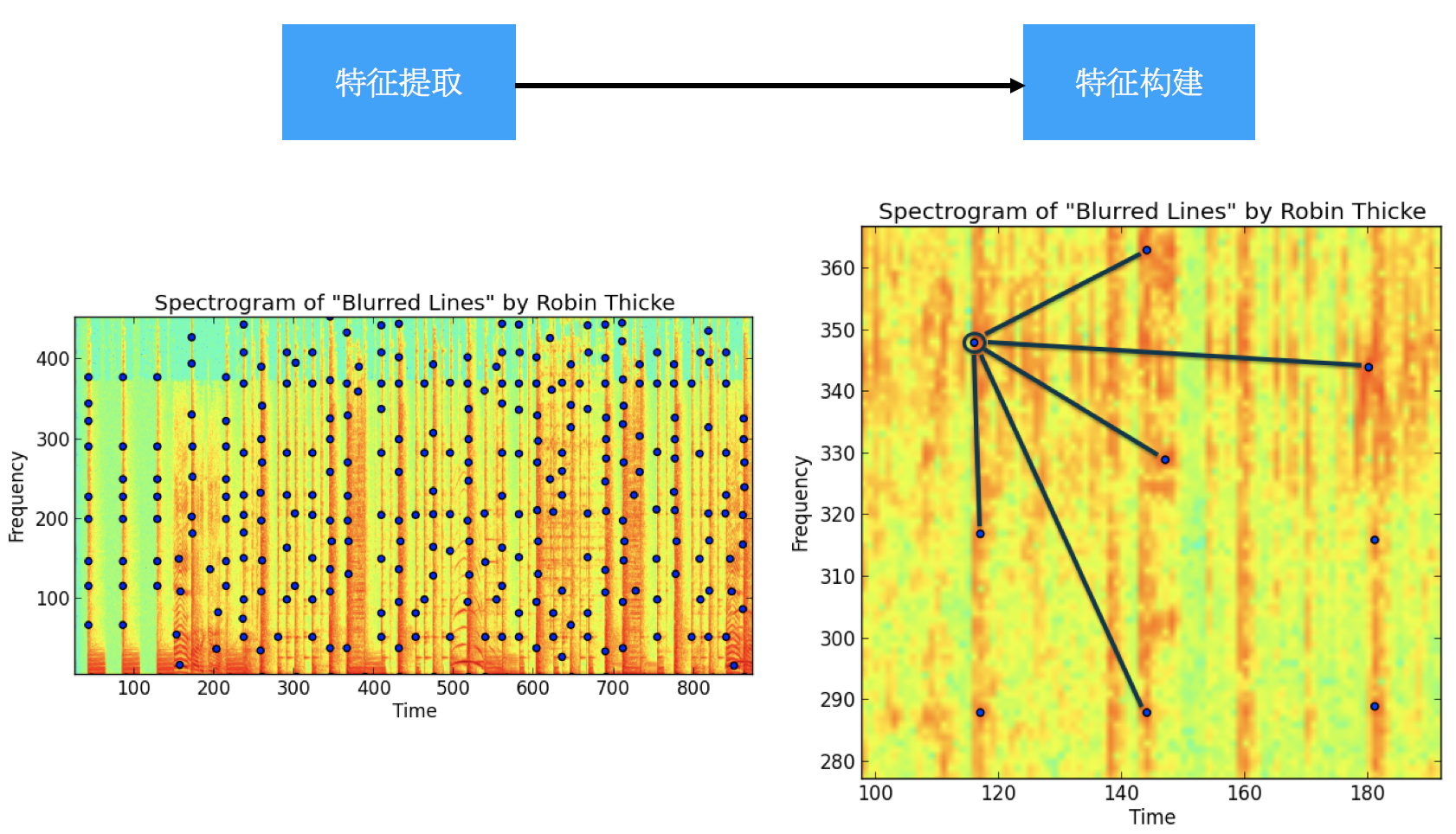
- 提取特征:图中提取的特征点就是频谱最大值点。
- 特征构建:特征是通过最大值点之间的距离来建模,例如本案例中就采用的是两个最大值点的距离、位置信息作为一个固定的特征作为音频特征信息。
有了上述音频特征后,就可以对两个不同音频进行检索,最大相似度的地方就是相似点。需要指出的是,这种技术最适用于录音片段的检索,如若音频内容相同但演绎方式不同(如不同人用不同语速、声调,使得提取的特征点不同)则无法有效识别。
有内容:语音识别、关键词检测
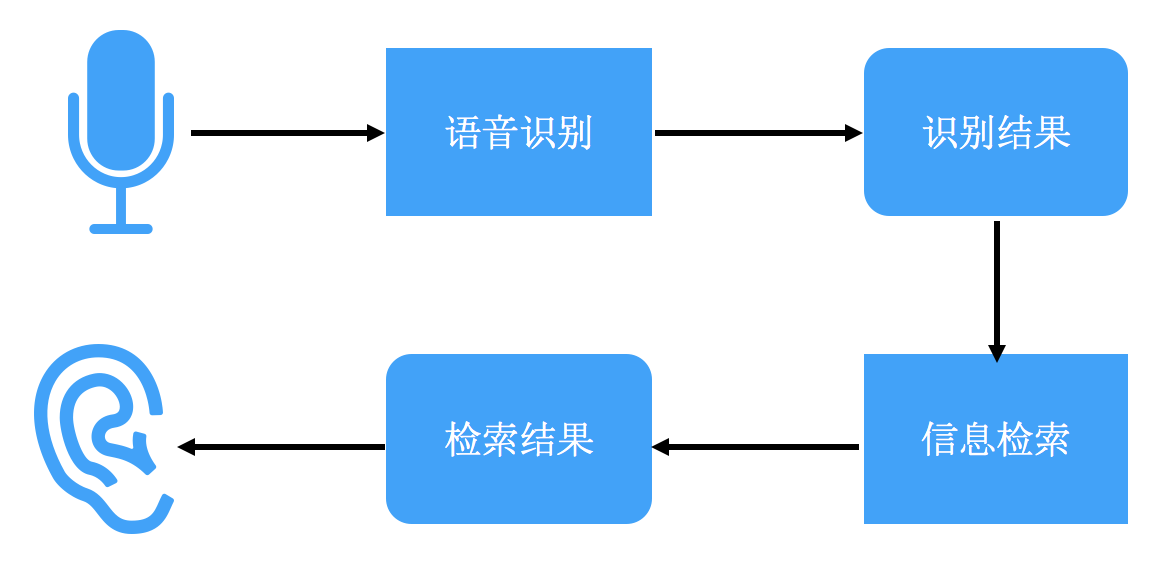
相比语音助手等其他语音交互相关应用,话务场景下的识别准确率更为关键。然而,在电话录音识别检测场景中,通话质量不佳会导致准确率下降。 改进方向:
- 不完全依赖ASR;
- 即使通话质量不佳,也能取得较好的检索效果。
语音关键词检出(STD)
语音关键词检出是从给定的语料数据中查询指定关键词是否出现的任务.该任务在语音检索、电话监控、舆情分析等领域具有广泛的应用.根据关键词的输入形式,该任务可以分为基于文本和基于语音样例两种类型:
- 传统的基于文本的关键词检出技术又称为关键词搜索(keyword search,KWS),通常基于一个大词汇量连续语音识别系统,在识别的NBest结果或者网格上进行搜索.
- 近年来,基于样例的语音关键词检出 (query-by-example spoken term detection,QbyE-STD)成为新的研究热点.
QbyE-STD目前通常有3种实现方法:
- 借鉴传统语音关键词检出的思路,称之为声学关键词检出(acoustic keyword spotting,AKWS).
- 借助其他语种成熟的语音识别系统进行解码,将查询样例和待检语音转换成音素序列或音 素网格,而后进行字符串匹配,该类方法称之为字符搜索(symbolic search,SS).此类方法通常采用加权有限状态机(weighted finite state transducer,WFST)建立索引并进行快速查找.
- 基于经典的模板匹配的思路,采用动态时间规整(dynamictimewarping,DTW)将查询样例和待查语句进行匹配.由于查询语句的时长通常远远大于样例时长,因此需要在语句上进行滑动查找,常用策略包括Segmental-DTW、Subsequence-DTW 、SLN-DTW (segmental local normalized-DTW)等。
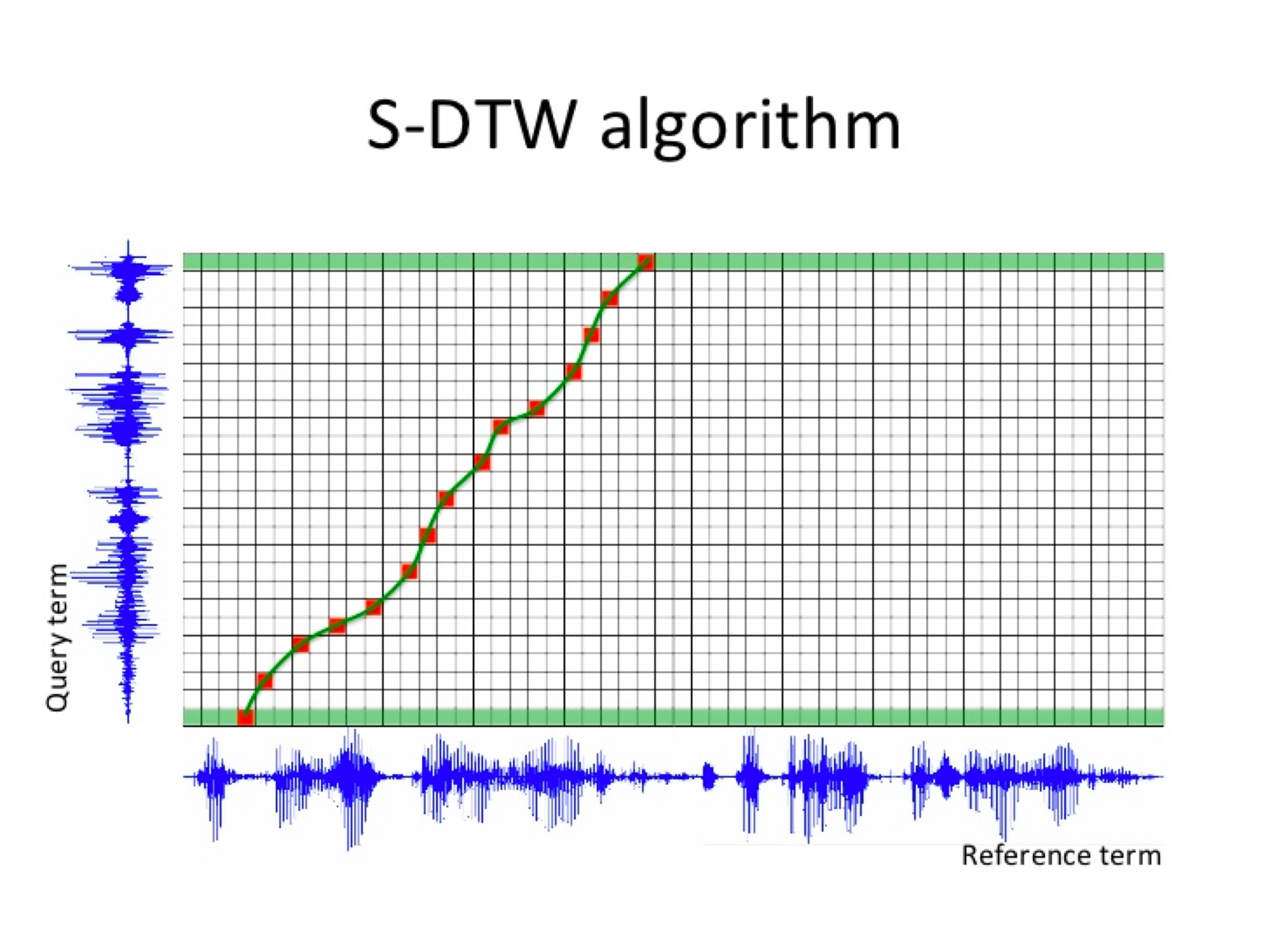
改进方案:音素识别
结合应用场景,使用语音关键词检索技术,将通话录音识别结果输出音频检索网络,将指定的语音关键词转换成音素在检索网络中进行匹配,输出检索结果。
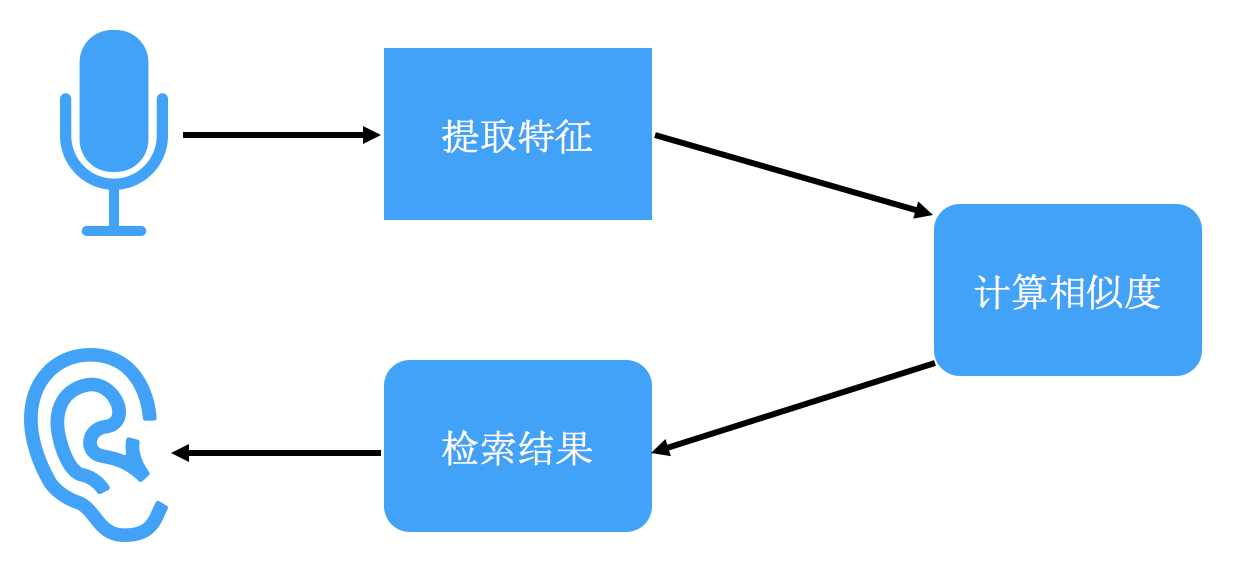
语音关键词检索
这种方式不仅绕开了生成文字所需的解码过程,提高检索效率,还能避免语音转文字可能带来的误差,提高识别准确率。例如将人名「张珊」转写成「张山」后就无法准确的检索正确的人名,而基于音素的检索是使用「zhang shan」进行匹配,很大概率上可以命中关键词。
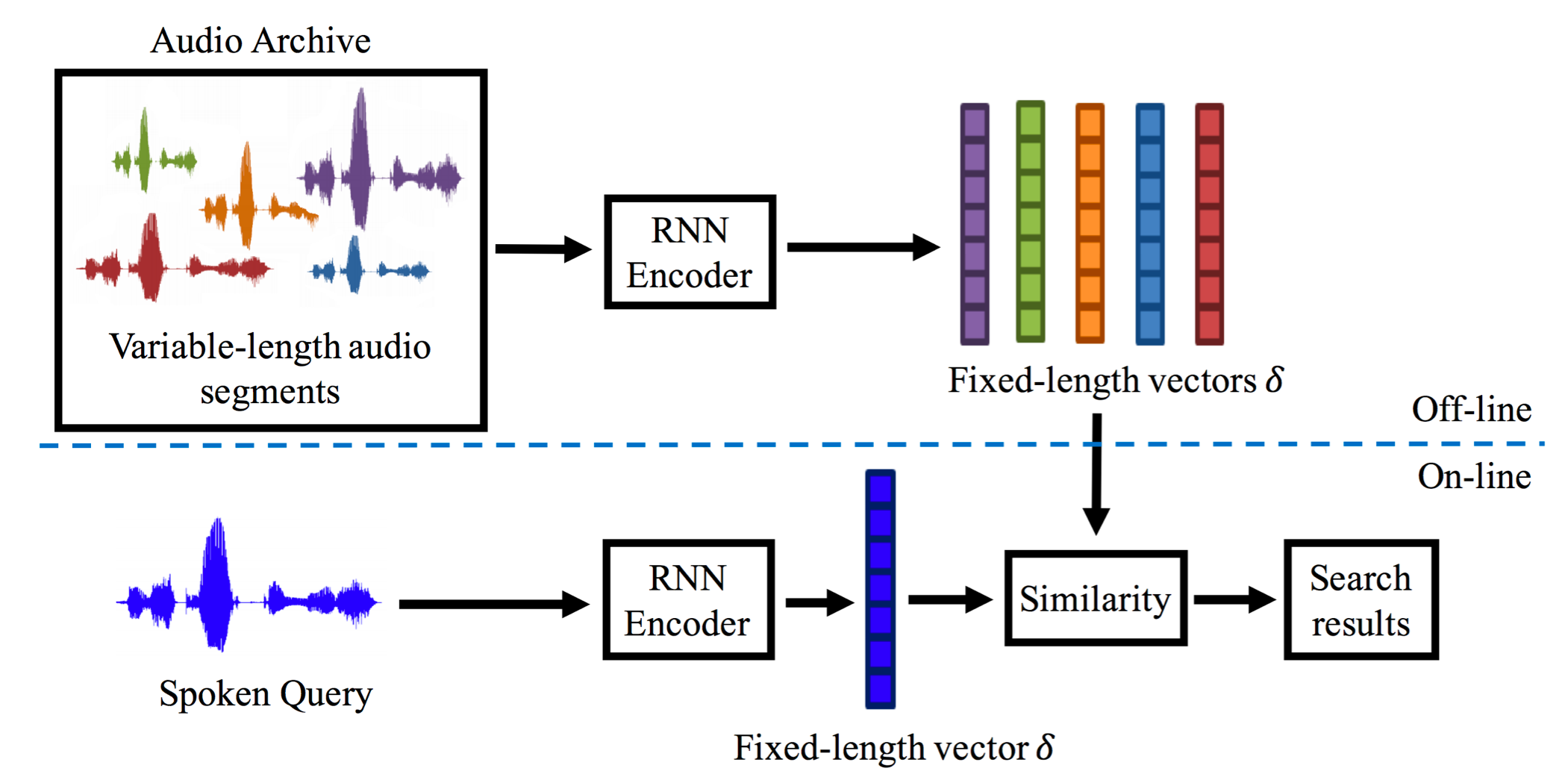
特征提取:识别音素
音素后验概率
给定一帧语音的谱特征向量\(a\),后验特征定义为在K个类别C1,C2,…,CK上的后验概率分布:
\(P = [P(C_1|a),P(C_2|a),\dots,P(C_K|a)]\)
\(P(C_i|a)\)谱特征(\(a\))在\(C_i\)(某个音素)上的后验概率,更好的鲁棒性(不同说话人)。
例如,类别定义为音素,训练基于HMM的音素识别器对语音数据进行解码,得到在每个音素上的打分即为音素后验特征。 与此类似,针对语音数据训练具有K个成分Gauss混合模型(GMM),然后对每帧语音数据在K个Gauss成分上打分,即可得到GMM后验特征(GMM posterior)。
一般来说,音素后验特征在基于DTW的QbE-STD任务中的效果最好。 但是对于少资源语言来说,在没有该语种的专家知识和标注数据的情况下,通常无法训练音素识别器。 借用其他语种的音素识别器(不匹配音素识别)来获得音素后验特征,是一种普遍采用的做法。 此外,采用机器学习方法自动发现某种语言中的“类音素”子词单元,获得类音素后验特征也是一种可行的方法。
1) CZ 音素后验: 布尔诺科技大学(Brno University of Technology,BUT)提供的捷克语音素识别器[16]在QUESST数据上解码获得的音素后验特征,音素个数为45。 2) HU音素后验: BUT提供的匈牙利语音素识别器[16]在QUESST数据上解码获得的音素后验特征,音素个数61。 3) RU音素后验: BUT提供的俄语音素识别器[16]在QUESST数据上解码获得的音素后验特征,音素个数为52。
CTC的tensorflow实现
实验数据
采集了16人(8男8女)的语音数据,每人20句话。通过DTW计算相似度,设定阈值判断是否是相同内容。
“当我还只有六岁的时候,在一本描写原始森林,名叫《真实的故事》的书中, 看到了一副精彩的插画,画的是一条蟒蛇正在吞食一只大野兽,下面就是那副画的摹本” “这本书中写道:’这些蟒蛇把它们的猎获物不加咀嚼地吞下,一会儿后就不能再动弹了,它们就在长长的六个月的睡眠中消化这些食物。’” …… ——截选自《小王子》
实验效果
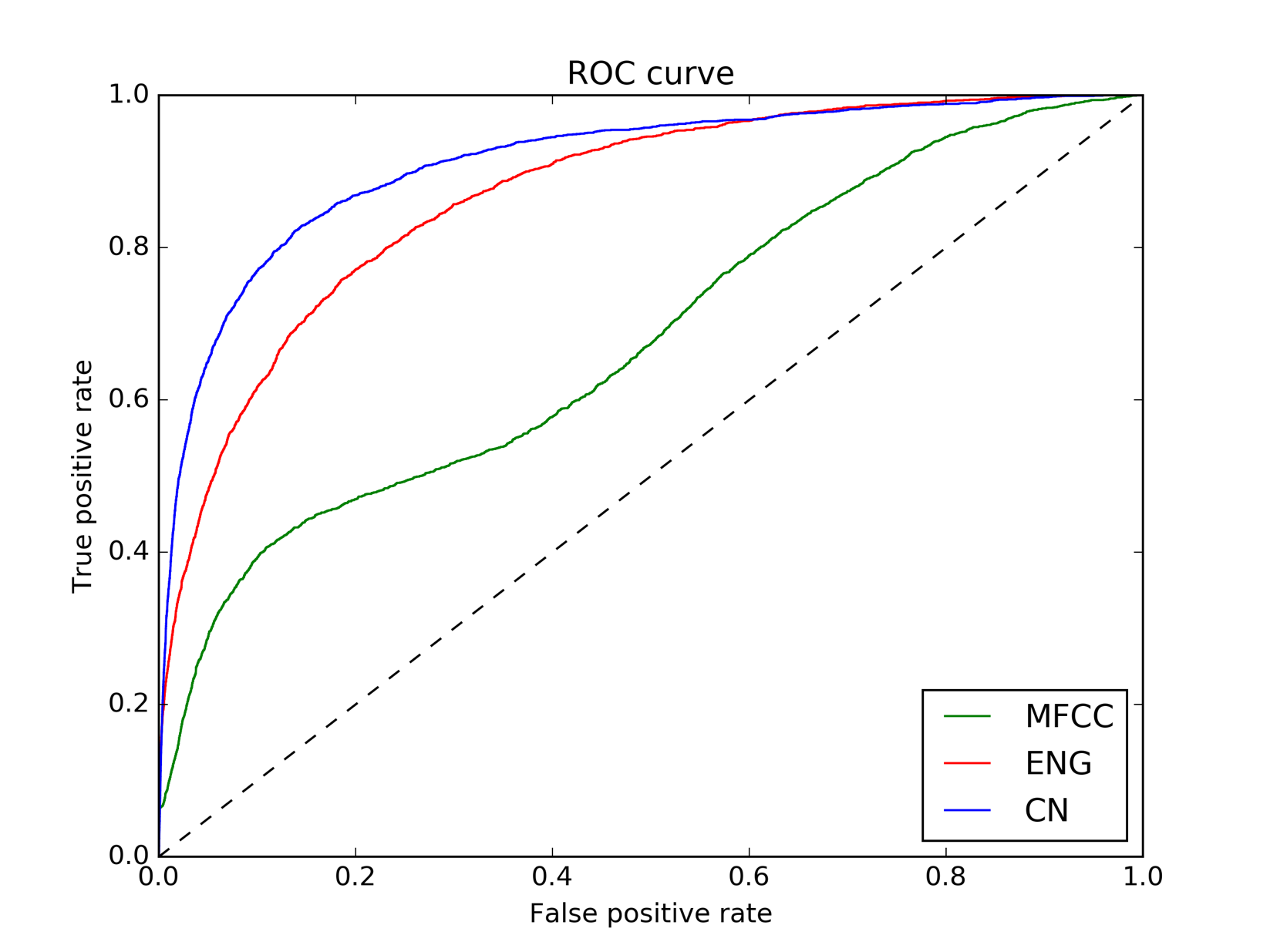
- 传统MFCC:对音频进行傅立叶变换,提取频谱能量分布特征
- 音素后验概率:训练音素识器,将音素识别结果作为特征
- 英文音素(39种)
- 中文音素(67种)
Reference
-
GTM-UVigo Systems for the Query-by-Example Search on Speech Task at MediaEval 2015,Paula Lopez-Otero, Laura Docio-Fernandez, Carmen Garcia-Mateo Spoken Audio Search (or Query-by-Example Spoken-Term Detection) Given a spoken query we search for matches (at lexical level) within a set of spoken documents • It is similar to Spoken Term Detection (NIST STD2006, OpenKWS) ut … Queries are spoken No prior information Different acoustic conditions “ear hi gforwhole do u e ts 6 lang. (Albanian, Chinese, Czech, Portuguese, Romanian, Slovak) • 19 hours of audio (dev = eval), per sentence segmentation • 450 queries/dev, 450 queries/eval • Recorded in isolation by different speakers (some non-native of the language) • Utterance-level matching • Recorded with context New! • 3 types of search • T1 - Exact match, dictated • T2 - Reordering and small variations, dictated • T3 - Reordering and small variations, conversational speech New!
- 基于分段动态时间规整和后验特征的中文语音模式发现
- 使 用 了 Brno 大 学 开 发 的 音 素 识 别 器 BUT来提取音 素 后 验 特 征。 约10h左右的中文广 播语料(TDT2 中文广播语料库),训练出中文音素识别器。 无论是有无词边界信息的 情况下,音素后验特征的效果总是明显优于 MFCC 特征,特 别 是 在 多 说 话 人 的 语 料 上,后 验 特 征 对 FMeasure的提升 更 大。 在 词 边 界 信 息 的 帮 助 下,语音模式发现的效果 提 升 明 显,不 仅 FMeasure 大大提高,在时间消耗上也要省得多。 寻求一种直 接在声学信息上找出词或短语边界的方法,才能真 正使这种优势体现出来。
Future work
Todo list
- 提升效率:DTW算法的时间复杂度是O(M x N),尝试使用监督学习方法训练端到端识别网络,降低时间复杂度;
- 文本关键词检索:先将文本关键词转化为对应的音素特征,再来进行检索。
- 不确定是否需要一些标准化的措施。
Things to learn
查询样例转换成音素序列后怎么查找
- 网格?
- 音素边界
补充
少资源语言关键词检出评测(QUESST)
跑通了上周提到的完成QUESST任务的一个项目,其使用的是BUT大学提供的phnrec工具来提取音素后验概率(音素模型是已经训练好的)。目前在Quesst数据集上跑通了,利用phnrec提取了自己采集的数据集的后验概率,之后还要进一步探索。
具体参考QUESST 2014 Multilingual Database for Query-by-Example Keyword Spotting
QUESST瞄准少资源语言的关键词检出,评测数据中包含多种少资源语言的未标注语音数据,语音文件来自不同录制环境和多种说话风格,部分语音文件带有较强的背景噪声。
QUESST 2014任务提供了包含23 h的检索语料库,共12492句话。 用于算法调试的发展集关键词560个,最终评测集关键词555个。 语料涉及斯洛伐克语、 罗马尼亚语、 阿尔巴尼亚语、 捷克语、 巴斯克语和英语等6种语言,其中英语部分多来自非母语说话人。 在评测任务期间,语料库不提供任何语种信息。
评测任务分为3种不同类型的查询:
- 1) 精确查询T1: 在语料库中找出与查询关键词精确匹配的地方。
- 2) 近似查询T2: 允许前后缀不同的匹配,例如给定的关键词是“friend”,可以匹配到语料库中包含“friendly”和“friends”单词的句子。
- 3) 近似查询T3: 在T2类型的基础上允许填充词和次序颠倒的匹配,例如给定的关键词为“white house”,在语料库中可以找到包含“house is whiter”的句子。
评测结果采用最小交叉熵(Cnxe)和TWV(term weighted value)来衡量。 为了计算这2项指标,参加评测的队伍需要提交每个关键词在语料库中每个句子上的打分,用以表示该关键词与该句子的匹配分数。
语音智能客服
电话诈骗识别
本文由 Rowl1ng 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
本文会经常更新,最后编辑时间为:2018-08-01 13:27:00